![[CSAPP] 5.10 Summary of Results for Optimizing Combining Code (최적화 코드의 결과 요약)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbVk9op%2FbtrYyVtdxvN%2FVky3km09DaibyFkKpdEhDk%2Fimg.png)
5.10 Summary of Results for Optimizing Combining Code
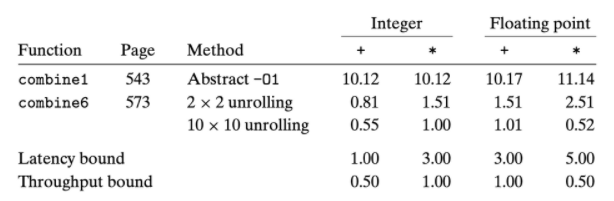
현재까지는 scalar code에 대한 CPE를 살펴봤었다. 즉, AVX vector 연산을 활용한 parrallelism을 살펴보진 않았다는 뜻이다.
여기까지의 여러 최적화로 인해 CPE들은 throughput bound 근처까지 내려가도록 했다.
→ 현재 성능을 제한하고 있는 것은 throughput bound 하나라는 얘기이다.
→ 이 때, 이 throughput bound를 결정짓는 요소가 바로 functional unit들의 capacity, 즉 해당 operation을 병렬로 처리 가능한 functional unit들의 수이다.
→ 이러한 처리로, 기존에 비해 10 ~ 20배 더 빠른 CPE를 달성했다.
→ SIMD(single instruction multiple data) 연산을 사용하게 된다면, 여기서 4 ~ 8배 더 향상시킬 수 있다.
Modern processor는 이러한 아주 강력한 computing power를 가진다. 하지만 이를 전부 이끌어내기 위해선 program을 그런식으로 짜야 한다는 것을 알 수 있다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [CSAPP] 5.12 Understanding Memory Performance(메모리 성능의 이해) (0) | 2023.02.08 |
|---|---|
| [CSAPP] 5.11 Some Limiting Factors(일부 제한 요인들) (0) | 2023.02.08 |
| [CSAPP] 5.9 Enhancing Parallelism(병렬성 향상시키기) (0) | 2023.01.30 |
| [CSAPP] 5.8 Loop Unrolling(루프 풀기) (0) | 2023.01.30 |
| [CSAPP] 5.7 Understanding Modern Processors(현대 프로세서 이해) (0) | 2023.01.30 |