![[CSAPP] 5.12 Understanding Memory Performance(메모리 성능의 이해)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FHcXXz%2FbtrYvnqcs2O%2FxtYKJSmecxYBqNGmP224jk%2Fimg.png)
5.12 Understanding Memory Performance(메모리 성능의 이해)
이제부터 memory 접근에 대한 성능을 살펴볼 것이다. 이 때, modern processor의 경우 하나 이상의 cache memory들을 가지고 있는데, 우리가 전제로 깔고 갈 상황은, memory에 대한 접근 중 data가 cache에 전부 있는 경우만이다 (이 cache memory에 대한 것은 6장에서 더 자세히 다룰 것이다).
Load and Store Operation
5.11장에서 봤듯이, functional unit 중 load unit과 store unit이 각각 load와 store 연산을 담당한다. 여기서 몇가지 특징들이 있다.
- 각 unit들은 memory 관련 연산 중 아직 pending 상태의 요청들을 유지하는 내부 버퍼가 있다.
- load unit : 각 unit당 72개의 pending 상태인 read 요청을 유지할 수 있다.
- store unit : 각 unit당 42개의 pending 상태인 write 요청을 유지할 수 있다.
- 각 unit은 한 cycle당 1개의 operation(request)의 수행을 시작할 수 있다.
5.12.1 Load Performance(로드 성능)
load operation을 포함한 프로그램에선 두가지 요소에 따라 성능이 좌우된다.
- pipelining의 수용력
- load unit의 latency
우리가 볼 예시에서의 CPE에서는 0.5 밑으로 내려가지 않았다. 이는 하나의 element당 한개의 load unit을 포함하고 있었기 때문이다. 조금 더 general하게 말하자면,
- 하나의 element당 k개의 value를 load하는 것을 포함한다면, CPE는 k/2 이하로 내려갈 수 없다.
왜 이런 식이 나왔는지는 이해가 좀더 필요하다.
이후에 설명이 더 있지만, 후에 더 읽어보자.. p.590 ~ p.591
5.12.2 Store Performance(저장 성능)
store operation
- load 연산과 마찬가지로 매 cycle마다 새롭게 store 연산을 시작 가능하다.
- 즉, memory write에 대한 연산들만 연속적으로 있으면, best CPE는 1.0이라는 뜻이다.
- single unit으로 달성할 수 있는 최대 CPE이다.
- 다른 register 값에 영향을 주지 않는다. → 즉, 연속된 store 연산이 있다고 해도 data dependency를 만들지는 않는다는 뜻
- 하지만 load 연산은 store 연산에 영향을 받는다.
- load 연산으로 이전 store연산이 write한 memory 주소에 접근할 수 있으므로
- 아래 두개의 코드를 살펴보도록 하자.위 write_read 함수를 호출하는 방법에 따라 Example A와 Example B로 나눠보도록 하자.



- Example A : src와 dest의 memory 위치를 달리 하여 write_read 함수를 호출하였다. → CPE 1.3
- Example B : src와 dest의 memory 위치를 동일하게 주고 write_read 함수를 호출하였다. → CPE 7.3
- Example B가 7 cycle이나 더 걸렸다.
Write/Read Dependency
memory read의 결과값이 최근 memory write에 의존하는 현상을 write/read dependency라고 한다.
- 위 Example A는 write/read depdency가 없다.
- 위 Example B는 write/read depdency가 있다.
processor는 이 dependency를 어떻게 감지하고 이를 위한 code를 어떻게 생성하는지를 알아보자. 이를 알아보기 위해선 load와 store unit의 세부적인 것들을 더 살펴봐야 한다.
store buffer
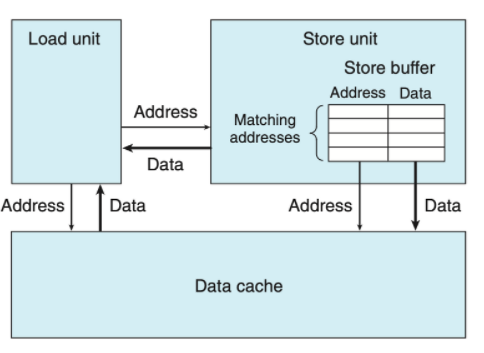
store unit이 가지고 있는 buffer를 store buffer라고 한다.
- store operation의 data와 address를 포함한다.
- 여기서의 store operation은 아직 끝나지 않은 operation들임을 인지하자.
- “끝났다” 라는 것은 어떤 의미일까? → data cache를 update하는 것까지를 포함한다.
- data cache란?
- 아래 modern processor의 설계를 보면서 봤던 data cache이다.
- 현재 우리는 모든 memory 관련 data가 이 data cache(cache memory)에 위치해 있는 경우만을 보고 있다고 5.12장 초반에 언급했었다.

- 이 store buffer로 인해, 연속된 store 연산이 들어와도, 다른 하나가 data cache를 update하는 것을 기다리지 않고 다른 store 연산을 실행시킬 수 있게 되었다.
load 연산과 store buffer
load operation이 실행될 때, 5.7장에선 data cache를 통해 data를 가져간다고 했다. 하지만, 이 data cache로 가기 전에 먼저 store buffer에 들린다.
- 먼저 store buffer에 들려 현재 load 연산의 주소와 동일한 주소가 이 store buffer에 존재하는지를 체크한다.
- 만약 있으면? → 해당 data를 load 연산의 결과로 가져온다.
- 없으면? → data cache에서 가져온다.
GCC가 생성한 assembly code와 data-flow

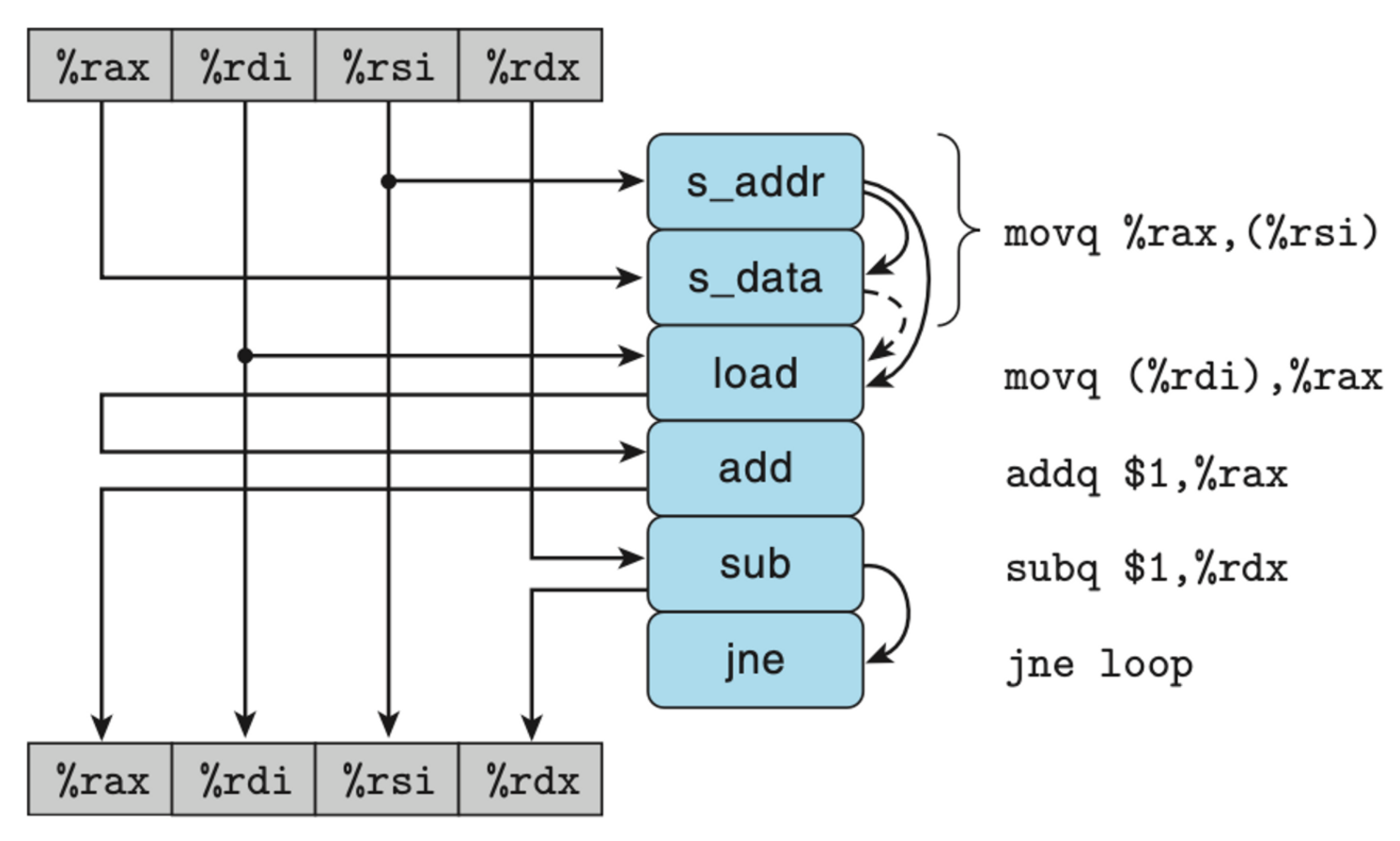


- movq %rax, (%rsi) → 두개의 operation으로 분리된 모습을 볼 수 있다. → s_addr & s_data
- s_addr : store operation의 address를 계산 → store buffer의 entry를 생성 → 그 entry에 계산한 address를 넣음
- s_data : 그 entry에 data를 넣음
- 즉, s_addr로 address가 store buffer에 세팅이 되어야만, data가 그 address가 있는 자리로 들어갈 수 있다.
- 이는 s_data 연산보다 s_addr 연산이 먼저 선행되어야 함을 의미한다.
- 또한 이렇게 선행되어야만 하는 것은 dependency가 있다는 것을 의미한다.
여기까진 store을 하는 movq instruction 안에서의 dependency이다. 그렇다면 load 와는 어떻게 dependency가 생기는지를 들여다보면 다음과 같다.
- movq (%rdi), %rax
- 여기서 load 연산이 발생한다.
- 이 때, 위에서 설명했다시피, load 연산은 data cache가 아닌 그보다 먼저 store buffer로 향한다고 했다.
- 미리 말하자면 s_data연산과 load 연산간에는 conditional dependency가 있다.
- 만약 load 연산의 주소와 일치하는 주소가 store buffer에 있다면?
- 그 주소에 있는 data를 가져오기 위해선 s_data 연산으로 먼저 data를 넣어놨어야 한다.
- 여기서 load 연산과 s_data간의 dependency가 발생한다.
- 만약 일치하는 주소가 없다면?
- s_data와 load 연산이 독립적으로 수행된다.
- 만약 load 연산의 주소와 일치하는 주소가 store buffer에 있다면?
- 그리하여 아래의 data-flow를 볼 수 있는 것이다.
- Example A는 load와 s_data간의 conditional dependency에서 dependency가 발생하지 않는 경우에 해당되는 것이고,
- Example B는 conditional dependency에서 dependency가 발생하는 경우에 해당되는 것이다.

- 따라서 processor는 다음과 같이 동작한다고 할 수 있다.
- operand가 모두 register일 경우 → operation이 어떻게 서로 영향을 끼치는지를 decode가 되자마자 알 수 있다. → 미리 예측 가능하다.
- memory reference가 하나 이상 있을 경우 → operation이 서로 영향을 끼치는지는 load와 store의 주소가 계산되고 같은지를 비교한 후에야 알 수 있다. → 미리 예측할 수 없다.
- 즉, 위에서의 질문을 다시 가져와보자.두 assembly code는 동일한데, processor는 어떻게 이 둘을 구분하고 실행을 달리하여 CPE가 차이가 나게끔 되는것인지가 의문이었다. 이제는 이 질문에 답을 할 수 있게 되었다.
- Answer
- store와 load의 각 주소가 계산이 된다.
- 각 주소를 비교하여 같은지 아닌지를 알아낸다.
- 같다면 Example B와 같은 실행을, 다르다면 Example A와 같은 실행을 하도록 한다.
- Answer
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [CSAPP] Chapter 06. The Memory Hierarchy(메모리 계층구조) (0) | 2023.02.09 |
|---|---|
| [CSAPP] 5.13 Life in the Real World: Performance Improvement Techniques(실제상황: 성능개선 기술) (0) | 2023.02.08 |
| [CSAPP] 5.11 Some Limiting Factors(일부 제한 요인들) (0) | 2023.02.08 |
| [CSAPP] 5.10 Summary of Results for Optimizing Combining Code (최적화 코드의 결과 요약) (0) | 2023.02.08 |
| [CSAPP] 5.9 Enhancing Parallelism(병렬성 향상시키기) (0) | 2023.01.30 |