![[CSAPP] 5.7 Understanding Modern Processors(현대 프로세서 이해)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbeGx8S%2FbtrXv3SBdkl%2FwLJHalqt9bZJXkARotHCi0%2Fimg.png)
5.7 Understanding Modern Processors(최신 프로세서 이해)
- 코드의 성능을 더 개선하기 위해서는 프로세서의 마이크로구조, 즉 프로세서가 instruction을 실행하도록 하는 하부 시스템 설계를 활용하는 최적화 기법을 고려해야 함.
- 성능 향상을 위해 현대 프로세서의 마이크로구조를 이해해야 한다.
- 현대 프로세서는 많은 트렌지스터들이 하나의 칩으로 구성되어 있기 때문에 현대의 마이크로프로세서는 프로그램 성능을 극대화시키는 복잡한 하드웨어에 적용될 수 있다.
- 실제 동작은 기계어 프로그래밍(machine level)에서와 다르다.
- 코드 레벨(code level)에서는, 한번에 하나의 instruction이 실행 되는 것처럼 보인다.
- 실제 프로세서에서는 여러 개의 instrucions이 동시에 평가된다. 이를 instruction-level parallelism이라 한다.
- 단순한 연속적인 instruction 가동상의 관점을 제시하면서 다수의 instructions을 병렬적으로 수행할 수 있는 복잡한 마이크로 구조를 사용하는 것이 현대 마이크로프로세서의 가장 큰 특징이다.
- 우리는 instruction-level parallelism을 달성하는 방법에 대해 이해해볼 것이다.
- 서로 다른 두 가지 lower bound가 최대 성능을 결정한다.
- latency bound(대기 시간 제한)는 다수의 연속되는 동작들이 엄격한 순서에 의해 실행될 때 발생한다.
- 이는 다음 동작이 시작되기 전에 이전의 동작에 대한 결과가 필요하기 때문이다.
- 코드의 데이터 의존성이 프로세서의 instruction-level parallelism을 제한하기 때문에 성능 저하가 발생한다.
- throughput bound(처리량 한계)는 프로세서의 기능 단위인 computing 용량으로 인해 겪는 한계이다. 프로그램 성능의 궁극적인 한계로 물리적인 한계이다.
5.7.1 Overall Operation(전체적인 동작)
- 아래 그림은 인텔의 프로세서 블록 다이어그램이다.

- 위와 같은 프로세서들을 superscalar라고 부르는데, 다수의 동작을 매 clock cycle마다 수행할 수 있고 out-of-order로 instruction을 실행하는 순서가 기계어 프로그램에서의 순서와 일치할 필요가 없다.
- chapter 4에서 배운 in-order 파이프라인과 달리 out-of-order인 점이 특징이다. 훨씬 더 복잡하지만 instruction-level parallelism을 훨씬 더 향상시킬 수 있다.
- ICU(Instruction control unit): 연속적인 instruction들을 메모리에서 읽고 프로그램 데이터에 대해 수행될 주요 primitive operation 집합을 생성한다.
- EU(Execution unit): 위 operations을 수행한다.
ICU(Instruction control unit)
- instruction cache(최근 접근한 instruction을 포함하는 매우 빠른 메모리)로부터 instruction들을 읽어옴.
- 프로그램이 branch을 만날 때, 프로그램이 가야하는 가능한 방향이 두가지로 나뉜다.
- 1. branch가 taken 될 때: branch target으로 control이 전달 된다.
- 2. branch가 not taken 될 때: instruction sequence에서 다음 instruction으로 control이 이동된다.
- branch란 조건적인 jump instruction을 의미.
- 여기서 현대의 프로세서는 branch prediction라는 기술이 이용된다.
- branch prediction이란 branch가 받아들여질지 아닐지 예측하고 branch의 target address까지 예측하는 것.
- 또한, speculative execution이라는 기술도 이용된다.
- speculative execution이란 branch prediction가 맞는지 틀린지가 확인되기 전에 fetching과 decoding instructions을 실행한다.
- 만약 나중에 branch 예측이 틀렸다는 것이 결정되면, branch point로 상태를 리셋하고 다른 instructions을 fetching 하고 실행한다.
- Fetch control라는 블록은 branch prediction을 수행하고 어떤 instruction을 fetch할 지 결정하는 작업을 수행한다.
Instruction decoding
- instrution을 instruction cache로 부터 읽어오는 과정. 실제 프로그램 instruction을 micro-operations이라고 불리는 primivie operation으로 변환한다. (instruction은 micro-operation들로 이루어 짐)
- x86 implementation에서 예시를 들어보겠다.
- addq %rax. %rdx는 single operation으로 변환된다.
- 반면, addq %rax, 8(%rdx)는 multiple operation으로 변환된다. 메모리 참조는 산술 연산(arithmetic operartion)으로 나눠지게 된다.메모리부터 프로세서로 값을 로드하고 로드된 값을 %eax 레지스터의 값과 더하고 결과를 메모리에 저장한다.
- 이렇게 나누어진 operation은 하드웨어 유닛들이 역할을 분담하게 된다. 따라서 이 유닛들은 instruction의 서로 다른 operation을 병렬적으로 실행할 수 있게 된다.
EU(Execution unit)
- instruction fetch 유닛으로부터 operation들을 받는다.
- 받은 operation들은 실제 작업을 수행할 functional 유닛들로 발송된다.
- functional unit은 여러 서로 다른 operation들이 각각의 작업을 수행할 수 있도록 전문화 되어 있다.
- 메모리를 읽거나 쓰는 작업은 load와 store 유닛에 의해 수행된다.
- load 유닛은 메모리로부터 프로세서로 데이터를 읽는 작업을 수행. 이 유닛은 주소 계산을 수행하기 위한 adder를 가진다.
- store 유닛은 프로세서로부터 메모리에 데이터를 쓰는 작업을 수행. 이 유닛은 주소 계산을 수행하기 위한 adder를 가진다.
- 위 그림과 같이 load 및 store 유닛은 data cache를 통해 메모리에 접근한다.
- data cache란 가장 최근에 접근한 data값을 저장하고 있는 매우 빠른 메모리
- speculative exectuion으로 수행될 때, 마지막 결과는 프로세서가 이 instruction들이 실제로 실행 되었는지 확인되기 전까지는 프로그램 레지스터나 데이터 메모리에 저장되지 않는다.
- Branch operation은 EU로 보내진다.
- branch prediction이 맞았는지 결정하기 위해서 eu로 보내지는 것이다. (branch가 가야 할 장소를 결정하기 위해서는 아님)
- 예측이 틀리면, EU 이후에 계산된 결과는 폐기.
- branch 유닛에 이 예측 결과가 잘못되었다는 것을 알려주고 올바른 branch의 목적지를 알려준다.
- 또한, 예측이 틀렸을 경우 branch 유닛은 새로운 위치에서 fetching을 시작한다.
- 예측이 잘못되면 성능에 많은 비용이 야기된다. 새로운 instruction들을 가져와 fetch하고 decode하고 fucntional unit까지 보내는 시간이 발생한다.
- 위 그림에서 Arithmetic operations이 두개가 있는 이유는 integer와 floation point 간의 다양한 조합들을 수행하기 위함이다.
- 만약 한 fucntion 유닛이 integer 연산에 전문화 되어 있고 다른 fucntion 유닛이 floation point 연산에 전문화 되어 있다면, multiple functional units을 갖는 완전한 이점을 얻을 수 없을 것이다.
- 예를 들면, Intel core i7 Haswell reference machine의 경우 8개의 functional unit이 있고 각각 0~7번까지 번호가 존재한다.
- 각각의 기능을 축약해서 보여주면 다음과 같다.

- 0번, 1번을 보면 하나의 function unit이 다양한 operation들을 수행하고 있음을 알 수 있고
- store 연산에는 두 가지 functional 유닛이 있음을 알 수 있다. 4번의 실제 data를 저장하는 fucntional 유닛과 7번의 저장할 address를 계산하는 functional 유닛이 있다.
- functional units들의 조합이 갖는 이점은 동일한 타입의 다수의 연산들을 동시에 수행할 수 있는 것이다.
- 위 머신에서 integer 연산을 수행할 수 있는 유닛은 4개 이고 2개는 load operation을 수행할 수 있고 나머지 2개는 floation point multiplecation을 수행할 수 있다. 이런 자원들이 프로그램 성능 향상에 어떤 영향을 끼치는 지 향후 확인할 것.
Retirement unit in ICU
- out-of-order은 병렬적으로 실행하고 순서가 확실하지 않아, 원래의 instruction의 순서대로 실행하기 위해 retriement unit이 존재.
- register file(integer, floation-point, SSE register, AVX register)을 포함하고 register들의 업데이트 control을 수행.
- instruction이 decoding 되면 해당 instruction에 대한 정보가 queue에 들어 감.
- 해당 정보는 두 가지 결과 중 하나가 발생할 때까지 queue에 남아 있는다.
- 1. instruction에 대한 operation이 끝나고, 이 instruction으로 이어지는 branch point가 올바른 예측으로 확인되면 이 instruction은 retire하고 프로그램 레지스터를 업데이트 할 수 있다.
- 2. 만약 instruction이 잘못 예측된 경우, instruction은 queue에서 flushed(삭제)되고 계산된 모든 결과들은 폐기된다. 이러한 방식으로 misprdiction은 프로그램 state를 변형시키지 않는다. (프로그램에 영향을 끼치지 않음)
- queue에서 정상적으로 수행되는 것을 instruction이 retire되는 것을 의미하고 프로그램 레지스터가 업데이트 된다.
- 위 그림에서 operation result를 볼 수 있다. EU들 간 화살표.
- 병렬적으로 실행되는 fuctional unit들이 다른 fuctinal unit의 연산 결과를 필요로하면 여러 파이프라인의 stage를 거치지 않고 직접적으로 전달된다.
- 이는 data-forwarding 기술의 더 정교한 기술이다.
- fucntional 유닛들이 operands를 전달하고 전달받는 동작을 communication이라 함. 이 메커니즘은 register renaming이라는 기술을 이용한다.
Register renaming
- register r을 업데이트 하는 instruction이 decode 된다.
- tag t가 생성된다. (tag t는 decode된 operation(register r을 업데이트 하는 instruction)에 대한 특정한 id이다)
- r과 tag t에 대한 쌍(r,t)을 table에 저장. (register와 tag의 관계를 의미)
- r을 이용하는 instruction이 decode 되면 register r 대신에 tag t를 operand로 해서 이 operation을 EU에 보낸다.
- EU가 첫번째 instuction을 끝낸 결과인 (v,t) 쌍을 생성한다.(v는 operation의 결과, t는 t를 operand로 갖는 operation)
- functional unit 들 중에 t를 operand로 갖는 unit은 이제 이 v를 사용해서 operation을 사용하게 된다.
- 위 같은 방식으로 data-forwarding이 이루어진다. register file에 읽고 쓰지 않고 operation들 사이에 직접적으로 forward된다.
- 이러한 방식으로 첫번째 operation이 종료되자마자 두번째 operation이 시작할 수 있다.
- 만약 decode된 instruction이 register r를 필요로 하고 관련된 tag t가 table에 없으면 register file에서 retire 한다.
- 결론적으로 register renaming을 하면 register들은 branch 결과가 확정된 후에 업데이트 되는 것임에도, operation들의 모든 sequence가 speculative하게 동작할 수 있다.
5.7.2 Functional Unit Performance(함수 유닛의 성능)

- 위 그림은 intel Core i7 Haswell processor의 Latency, isuue time, capacity 수치들을 표현한 것
- Latency: 실제 연산을 수행하는데 걸린 클럭 사이클 수. (operation의 전체 수행 시간)
- issue time: 같은 종류의 독립된 두 연산 사이에 소요되는 최소 사이클 수
- 같은 종류의 operation이 연이어 있다면 하나의 operation을 시작한 후 다른 operation을 시작하기 전까지 걸리는 클럭 사이클 수
- capacity: 해당 연산을 수행할 수 있는 functional unit의 수
- issue time이 1인 것은 하나의 operation을 수행 후 바로 다음의 operation을 시작할 수 있는 것을 의미. 이는 pipelining 기술 덕분에 가능하다.
- pipelined function unit은 일련의 stage로 이루어진 fucntion unit이다.
- 예를 들어, floating-point adder은 3개의 stage로 이루어진다. 1. exponent value 계산 2. fraction add, 3. 결과 반올림
- 이러한 방식으로 arithmetic operation들은 연속적인 stage들을 통해 이루어질 수 있다.
- issutime이 1인 functional unit들은 fully pipelined라고 불러진다.
- fully pipelined는 매 클록 사이클마다 새로운 operation을 실행할 수 있다.
- 예를 들어, divider의 경우 pipeline 되어 있지 않다. 이는 latency와 issue time이 같은 것을 의미.
- latency와 issue time이 같은 것은 한 division이 완벽하게 끄나야 다음의 새로운 division이 수행될 수 있는 것을 의미한다.
- division은 나누는 수와 나눠지는 수의 조합에 따라 추가적인 단계가 더 필요하게 된다.
- 이는 latency와 issue time이 증가되는 것을 의미하기에 비용이 더 많이 든다.
- division 연산의 경우 짧은 latency를 가지거나 pipeling으로 구현하지 않은 이유는 추가적인 하드웨어가 필요하고 하나의 마이크로프로세서 칩은 제한된 면적을 갖기 때문에, CPU 설계자들은 functional unit들의 수들과 최적의 전체적인 성능을 위해 균형을 맞추기 위해 unit의 수에 제한을 둔다. 따라서 division은 상대적으로 발생 빈도가 적고 short latency나 fully pipelining으로 구현하기 어렵다.
maximum throughput of the unit
- issue time을 표현하는 또 다른 방식이다.
- fully pipelined fuctional unit은 1 opearation per clock cycle을 maximum throughput으로 가진다.
- 반면, higher issue time unit은 더 낮은 maximum throughput을 가진다.
- multiple functional unit을 가지는 것은 throughput을 더 높인다.
- 이를 C(capacity) / I(issue-time)으로 maximum throughput으로 나타낼 수 있다.
Two fundamental bounds on the CPE values

- latency bound: 엄격한 순서대로 실행되는 operation의 조합이 수행되는데 필요한 최소 CPE 값
- throughput bound: functional 유닛이 처리할 수 있는 최대량의 따른 최소 CPE 값
- 예를 들어 한 개의 fucntional unit(integer multiplyer)이 1 isuue-time을 갖는다면, thruoghput bound는 1이다.
- 또한, load unit이 두 개 있는 상황에서 functional unit(integer addition)이 4개 일 때, operation이 load operation을 포함하기에 최대 2개 까지 처리 가능.
5.7.3 An Abstract Model of Processor Operation
- 현대의 프로세서에서 실행되는 프로그램의 성능을 분석하기 위한 도구로 data-flow를 사용할 것이다.
- data-flow는 데이터 의존성들이 어떻게 서로 다른 operation들 사이에서 실행되는 순서를 제한하는지 그래픽컬하게 보여주는 것을 의미. 이런 제한은 critical paths 라는 graph로 나타낼 것.
combine4의 CPE측정

- combine4의 CPE가 프로세서의 Latency bound와 매칭되는 것을 알 수 있다.
- L * n + K clock cycles
- L: operations의 latency
- n: elements 수
- K: 함수를 호출하거나 루프를 시작 또는 종료할 때의 오버헤드
- CPE는 Latency bound L과 동일하다.
From Machine-Level Code to Data-Flow Graphs
//Inner loop of combine4. data_t = double, OP = *
//acc in %xmm0, data+i in %rdx, data+length in %rax
.L25: //loop:
vmulsd (%rdx), %xmm0, %xmm0 //Multiply acc by data[i]
addq $8, %rdx //Increment data+i
cmpq %rax, %rdx// Compare to data+length
jne .L25 //If !=, goto loop
- type은 dobule형, operation은 multiplication 일 때, 어셈블리 코드 보면
- %rdx는 i번째 요소를 가리키는 pointer를 가지고 있고
- %rax는 array의 끝을 가리키는 pointer를 가지고 있고
- %xm0는 누적된 값 acc를 가지고 있다.
- 우리의 가상 프로세서 설계에 의하면, 어셈블리 4개의 instruction들은 위 그림과 같이 5개의 operation들로 decode된다. 첫 multiplication instruction 은 load operation과 mul operation로 확장된 것
- 위 그림을 설명하면, box와 line들로 표현된 것은 레지스터들이 위의 opeartion 들에 의해 어떻게 사용되고 어떻게 갱신되는 지를 나타낸 것이다.
- 상단 레지스터: 루프의 초기 레지스터들의 값들을 의미
- 하단 레지스터: 루프가 끝났을 때의 값들을 의미
- %rax 레지스터의 경우 cmp operation에서만 쓰인다.
- 또한, %rdx 레지스터의 경우 루프 안에서는 load와 add operation으로 사용되고 add operation으로 생성된 값으로 업데이트 된다.
- 곡선의 화살표는 직접 바로 전달되는 것을 의미한다. 앞서 말한 data-forwarding이다.
- load operation에서 메모리로 부터 읽고 바로 직접 mul operation으로 전달
- 하나의 vmulsd instruction으로부터 decoding 된 load와 mul operation이기에 전달을 중간에서 담당하는 레지스터가 존재하지 않아 직접 전달 된다.
- cmp operation에서 condition code들을 업데이트하고 이 condition code들은 jne operation에 의해 평가 됨.
- 루프를 구성하는 코드 부분에서 레지스터들의 4개 분류
- 1. Read-only: 데이터 또는 메모리 주소를 계산하기 위한 source 값들로 사용된다. 변경은 되지 않고 사용되기만 하는 register로 %rax에 해당한다.
- 2. write-only: 데이터 이동 연산의 destination으로 사용된다. 그림의 루프에서는 존재x
- 3. Local: 루프 내에서 사용되고 업데이트 되지만, 한 반복에서 다음 반복 사이에 의존성이 없다. conditional code register이 그림 루프에서의 예시이다. 이는 cmp에 의해 갱신되고 jne 연산에 의해 사용된다.
- 4. Loop: 루프 내에서 source 값과 destination으로 사용된다. 한 반복에서 생성된 값이 다음 반복에서 사용된다. %rdx, %xmm0이 여기에 해당.

- 5.13 그림을 더 graphical 하게 표현하면 위 그림과 같다.
- (a)는 data flow를 더 명확하게 표현했다.
- whtie operation은 프로그램의 data flow에 직접적인 영향을 주지 않은 operation이다.
- cmp와 jne은 ICU에서 branch가 받아들여질 것이라는 branch prediction을 통해 operation의 흐름이 결정되므로 data flow에 직접적인 영향이 없다. (branch condition을 평가하고 결과를 ICU에게 알리는 작업이 충분히 속도가 빨라서 프로세서 속도에 영향을 주지 않는다고 가정)
- whtie operation은 프로그램의 data flow에 직접적인 영향을 주지 않은 operation이다.
- (b)는 white operation을 제거하고 오로지 루프 레지스터 간에 data dependency를 보여준다.
- load - mul 간의data dependency: load에서 계산된 값을 mul에서 사용
- load - add 간 data dependency: load에서 이전 값이 사용되고 add에서 해당 값을 갱신한다.
- %rdx는 i번째 요소를 가리키는 pointer를 가지고 있고
- %rax는 array의 끝을 가리키는 pointer를 가지고 있고
combine4를 n번 반복한 data flow는 다음과 같다
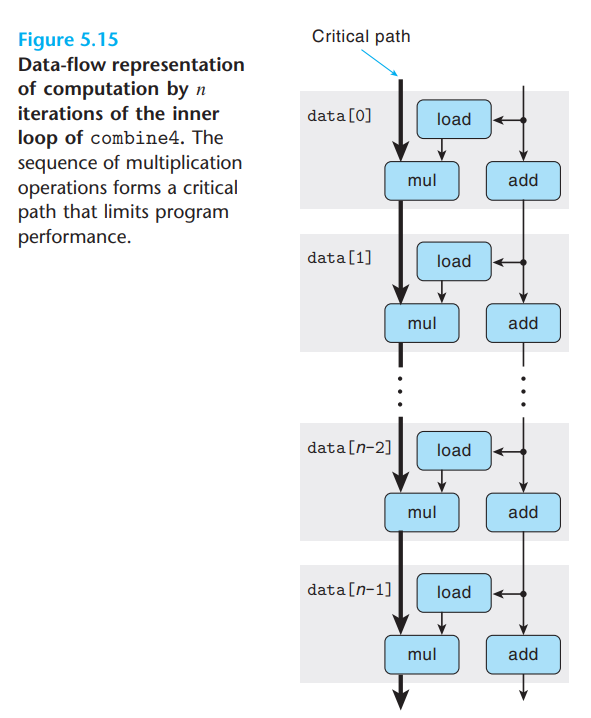
- mul과 add의 latency는 각각 5, 1이다.
- 이는 mul operation의 수행 시간이 지배적이라는 의미이고 mul operation으로 부터 화살표가 critical path가 된다.
- 이 그림은 latency가 1보다 큰 operation의 경우, 이 operation의 화살표가 프로그램의 성능을 제한하는 critical path를 구성한다.
- critical path의 길이는 L(latency) * n(요소의 수)으로 표현되고 L는 CPE와 같다.
Other Performance Factors
- Critical path는 프로그램이 필요하는 최소 cycle에 대한 lower bound만 제공.
- 사용 가능한 functional unit의 총 개수와 fuctional unit 사이에서 전달될 수 있는 데이터들의 수도 프로그램의 성능을 제한할 수 있다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [CSAPP] 5.9 Enhancing Parallelism(병렬성 향상시키기) (0) | 2023.01.30 |
|---|---|
| [CSAPP] 5.8 Loop Unrolling(루프 풀기) (0) | 2023.01.30 |
| [CSAPP] 5.6 Eliminating Unneeded Memory References(불필요한 메모리 참조 제거) (0) | 2023.01.30 |
| [CSAPP] 5.5 Reducing Procedure Calls(프로시저 호출 줄이기) (0) | 2023.01.30 |
| [CSAPP] 5.4 Eliminating Loop Inefficiencies(루프 비효율성 제거하기) (0) | 2023.01.30 |