![[CSAPP] 3.11 Floating-Point Code(부동소수점 코드)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FctHOLU%2FbtrW1OPkovk%2F4jF5ZS6tZh1hE7PnKJN1o0%2Fimg.png)
학습 주제
- Floating-point data에 대한 architecture와 여러 instruction들, 그리고 여러 convention(passing as arguments, returning 관련)에 대해 학습할 것이다.
정리한 내용
3.11 개요 - Floating-point architecture
processor를 위한 floating-point architecture는?
- ‘프로그램이 동작하는 machine에 매핑된 floating-point value’에 동작하는 방식에 영향을 끼치는 다양한 관점들로 구성된다.
다양한 관점들은 다음과 같다.
- 어떻게 floating point value들이 저장되고 접근되는지 → 이것은 몇몇 형태의 register에 의해 이뤄진다.
- floating-point data에 동작하는 instruction들
- function에서 인자로 넘겨질 때와 반환될 때 사용되는 convention(규칙)들
- function이 호출되는 동안 어떻게 register를 보존할 지 → caller saved인지 callee saved인지
3.11 Floating-Point Code(부동소수점 코드)
3.11 - floating point architecture의 역사
미리 알아야 할 것
- multiple operation : single instruction, multiple data(SIMD)를 수행하는 것을 multiple operation이라고 한다(병렬적으로 여러개의 data를 동시에 조작)
- scalar operation : single instruction, single data를 수행하는 것을 scalar operation이라고 한다(하나의 한개의 data만 조작)
- media instruction : parallel mode에서 수행되는 instruction이다(SIMD를 수행하는 instruction).
- 처음에는 parallel mode에서만 수행
- SSE2 이후 scalar mode에서도 수행 가능해짐
- 지금부터 볼 architecture들은 전부 MM 이라고 부르는 register set들을 가지고 있다.
MMX
- Pentium/MMX(1997)부터 소개
- 이 때 image & graphic을 처리하기 위한 media instruction들을 지난 연이는 세대들 것 까지 통합.
- register set : MM (8byte)
SSE
- streaming SIMD Extension
- register set : XMM (16byte)
AVX
- Advanced Vector Extension
- register set : YMM (32byte)
SSE2
- Pentium4(2000)에 소개
- 이때부터 이런 media instruction들이 floating-point data의 연산에 한하여 scalar operation들을 수행하게 되었다(floating-point에서는 scalar operation만 수행된다는 건 아니다. multiple operation도 수행된다. 단지 scalar operation이 media instruction에 도입이 되었다는 것에 focusing하면 좋을 것 같다).
- scalar operation을 수행할 땐, XMM이나 YMM의 하위 32-bit(float), 또는 하위 64-bit(double)을 사용한다.
- 이러한 scalar mode에선 기존 processor의 floating-point data를 지원하는 방식에 있어 더 전형적인 register set과 instruction들을 제공하게 되었다.
- x86-64 code를 수행할 수 있는 모든 processor들은 SSE2나 그 이상을 채택하고 있다.
- 따라서 x86-64에서 floating-point는 SSE나 AVX를 기반으로 한다(함수의 인자로 넘길 때나 return할 때 등의 상황에서).
그 외
- 이 책은 AVX2를 기반으로 한다. (Core i7 하스웰 processor, 2013)
- GCC는 -mavx2 로 compile할 시 AVX2 code를 생성해준다.
- SSE의 여러 버전들은 개념적으로 동일하긴 하지만 instruction의 이름과 format이 다르다.
- 여기선 gcc 로 compile할 때 나오는 instruction들만 볼려고 한다. 대부분이 scalar AVX instruction이고, 간혹 entire vector에 대한 동작이 발생하는 경우도 설명하긴 할 것이다.
- 어떻게 SIMD능력을 더 갈굴지는 Web Aside OPT:SIMD(p.582)를 참고하자.
- Intel과 AT&T의 assembly format은 서로 다르다.

Figure 3.45 Media registers. 위에 보면 floating-point data에 대한 return을 할 경우 %xmm0 register를 이용하는 것을 알 수 있다. 또한 argument로 어떤 것을 이용하는지를 확인할 수 있다.
3.11.1 Floating-Point Movement and Conversion Operations(부동소수점 이동 및 변환 연산)

Movement
- Memory - XMM register or XMM register - Memory
- vmovss, vmosd instructions
- memory 참조는 항상 scalar mode로 수행한다.
- 이 instruction들은 data의 alignment는 신경 안써도 된다.
- data alignment란? code optimization의 가이드라인에 따르면,
- 32-bit memory data는 4-byte,
- 64-bit memory data는 8-byte
- Integer의 mov와 동일하게 memory참조에 있어서 D(B, I, S) (Displacement, Base register, Index register, Scale factor) 형태 전부 사용이 가능하다.
- XMM - XMM register
- vmovaps, vmovapd instructions
- entire copy를 수행한다(parallel mode로 동작) → 즉, 위의 경우에는 scalar mode로 동작한다.
- entire register를 copy하는 방식이나 low-order value만을 copy하는 방식이나 기능 또는 실행속도 등에 영향이 없다고 한다.
- 따라서 scalar data에 특정한 instruction가 아닌 이런 명령어를 사용하는 것엔 실질적인 차이가 없다.
- 이 instruction들의 a 글자가 들어가는 이유 : instruction에서 사용하는 operand에 위에서 나온 alignment가 되어 있지 않을 경우 Exception을 발생시킨다는 의미를 가진다.
- 단, 이 data alignment의 경우, memory관련 read와 write에만 강제되는 조건이므로 현재 XMM - XMM 간의 movement에서 사용되고 있기에 instruction들의 a 글자의 효과는 없다. (XMM은 memory가 아닌 register이므로)
- GCC의 경우
- scalar instruction을 memory ↔ XMM 인 경우에만 사용한다.
- XMM - XMM일 경우엔 vmovaps, vmovapd instruction 둘중 하나를 사용한다.
- 예시
float float_mov(float v1, float *src, float *dst) {
float v2 = *src;
*dst = v1;
return v2;
}
Conversion
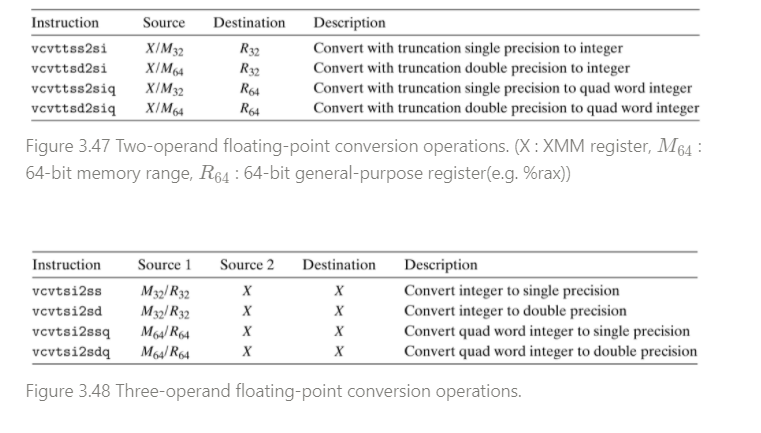
floating-point → integer data types
- vcvttss2si, vcvttsd2si, vcvttss2siq, vcvttsd2siq
- XMM이나 Memory로부터 floating data를 읽어온다.
- General-purpose register에 write(저장)한다.
- 이 때 truncation이 발생한다 → 1의 자리로 (toward zero rounding)
- 이 truncation 때문에 cvt 뒤에 t 글자가 하나 더 붙는다.
integer → floating-point data types
- vcvtsi2ss, vcvtsi2sd, vcvtsi2ssq, vcvtsi2sdq
- 보기드문, 3개의 operand를 갖는다.
- 첫번째 operand : source
- general-purpose register나 memory 영역에서 data를 읽어온다.
- 두번째 operand
- 이건 이 책에서 생략하려 함. 목적과 부합하지 않아서라고 함.
- 기능으로는 상위 byte에만 영향을 끼친다고 한다.
- 세번째 operand : destination
- 무조건 XMM이어야 한다.
- 보통은 2번째와 3번째 operand를 동일하게 한다.
single → double conversion
- single에서 double로 converting을 해주는 vcvtss2sd 라는 명령어가 있다. 이 명령어를 사용해서 변환하려고 할 때 다음과 같은 code를 생각할 수 있을 것이다.
- vcvtss2sd %xmm0, %xmm0, %xmm0 ← %xmm0의 하위 4byte에 single-precision value가 담겨있다고 할 때, %xmm0의 하위 8byte에 결과가 저장됨을 기대할 수 있다.
- 하지만 GCC가 생성하는 코드는 달랐다.
vunpcklps %xmm0, %xmm0, %xmm0
vcvtps2pd %xmm0, %xmm0- vunpcklps instruction
- 기능 : first와 second operand의 data를 third operand에 상호 배치한다.
- 예) first operand : $[s_3, s_2, s_1, s_0]$, second operand : $[d_3, d_2, d_1, d_0]$ 가 있을 때, 이 연산의 결과는 $[s_1, d_1, s_0, d_0]$ 이 된다.
- 이런 형식으로 상호배치가 된다는 뜻
- 위 code를 다시 예로 들어보면 다음과 같다.
- first와 second operand는 %xmm0으로 모두 같으므로 둘 모두 $[x_3, x_2, x_1, x_0]$ 이 담겨 있다고 할 수 있다.
- 위 vunpcklps 명령어를 통해 다음과 같은 결과가 나온다. → $[x_1, x_1, x_0, x_0]$
- vcvtps2pd instruction
- 기능 : XMM에 담겨 있는 하위 두개의 single precision value를 두개의 double precision value로 확장하여 XMM에 넣는다.
- 예) 위 vunpcklps 연산 이후 $[x_1, x_1, x_0, x_0]$이 나왔다. 이 결과에 vcvtps2pd 연산을 하게 되면 다음과 같은 결과를 얻을 수 있다. → $[dx_0, dx_0]$.
- 이렇게 2개의 확장된 double precision value가 XMM에 저장된다.
- ※ $dx_0$ : $x_0$ 가 double precision으로 확장(or converting)된 수.
※ 왜 처음 기대한 코드 vcvtss2sd %xmm0, %xmm0, %xmm0 얘를 사용하지 않고 GCC는 위 두개의 instruction으로 이루어진 code를 생성했을까?
- 연속적으로 이 두개의 연산을 수행함으로써 얻는 효과는?
- %xmm0의 하위 4byte에 들어있는 single-precision value를 double-precision value로 변환함
- 그리고 %xmm0에 변환된 double-precision value의 복사본 ‘두개’를 저장함
- GCC가 왜 이런 code를 생성하는지는 명확하지 않다고 한다.
- benefit도 없고, 이렇게 XMM register를 복사할 이유도 없다.(그래서 더욱 왜 이렇게 했는지 모르겠음.)
double → single conversion
vmovddup %xmm0, %xmm0 ;Replicate first vector element
vcvtpd2psx %xmm0, %xmm0. ;Convert two vector elements to single
- vmovddup instruction
- %xmm0에 double-precision value인 $x$ 가 두개 저장되어 있었다면 ($[dx_1, dx_0])$.
- 기능 : $[dx_0, dx_0]$ 로 duplicate를 한다. ($dx_0$ : 8byte double-precision data)
- 즉, 하위 8byte의 data를 duplicate해서 두개의 8byte data를 second operand에 저장한다는 뜻
- vcvtpd2psx instruction
- 기능 : 위의 결과로 %xmm0에 저장된 $[dx_0, dx_0]$의 data들을 single-precision으로 변환한다.
- 그 이후 XMM의 하위 절반의 byte에 두개의 single-precision value들을 저장하고, 나머지 상위 절반은 0으로 채운다.
- 기능 : 위의 결과로 %xmm0에 저장된 $[dx_0, dx_0]$의 data들을 single-precision으로 변환한다.

3.11.2 Floating-Point Code in Procedures(프로시저에서 부동소수점 코드)
Floating-point data가 인자로 넘겨질 때와 return 될 때의 경우를 살펴볼 것
인자 전달
- XMM register를 이용해서 총 8개까지 인자로 넘길 수 있다. → %xmm0 ~ %xmm7을 사용
- 만약 인자가 8개가 넘는다면, 나머지는 stack에 쌓아놓는 방식으로 동작한다.
반환
- Floating-point data를 반환할 때는 오직 %xmm0 register만을 사용한다.
- 반환 값을 %xmm0에 저장하는 방식
다른 convention들
- 모든 XMM register들은 모두 Caller saved이다.
- 즉, callee에서는 이 XMM register들을 따로 미리 저장해둘 필요 없이 덮어 씌워 자유롭게 사용이 가능하다.
- ※ callee saved register인 경우에는 만약 callee가 미리 저장을 해두지 않고 해당 register에 다른 값으로 덮어 씌워 저장하게 된다면, 원래 있던 값을 잃어버리게 된다. → 이는 원치 않는 동작을 야기한다.
- 여러 인자가 섞여 들어올 땐?
- integer와 pointer data type들은 모두 general-purpose register를 이용하고, floating-point data type의 경우 XMM register로 인자를 전달한다.
- 이 때, 각각의(general-purpose register와 XMM register 각각의) 인자 전달 시의 ordering을 각각 지켜야 한다.
- 예) double f1(int x, double y, long z) 의 경우
- x는 %rdi(혹은 %edi)를 통해
- y는 %xmm0 을 통해
- z는 %rsi를 통해
Practice Problem 3.5.2
double g1(double a, long b, float c, int d); // A
double g2(int a, double *b, float *c, long d); // B
- 정답
A) %xmm0, %rdi, %xmm1, %esi
B) %edi, %rsi, %rdx, %rbx3.11.3 Floating-Point Arithmetic Operations(부동소수점 산술연산)
산술 연산에 동작하는 Scalar AVX2 Floating-point 명령어를 알아볼 것이다.

Figure 3.49 Scalar floating-point arithmetic operations. 하나의 arithmetic operation에 대해 single과 double 각각 따로 instruction이 있는 것을 알 수 있다.
operand
source operand를 s1 하나만 가지고 있는 instruction들도 있고, s1, s2 두개를 가지는 instruction들도 있다.
- s1 : XMM register와 Memory location이 올 수 있다.
- s2 : XMM register만 올 수 있다.
- destination D : XMM register만 올 수 있다.
각 연산들은 single-precision과 double-precision value에 대응하는 instruction들이 각각 있다.
코드

- 인자 a, x, b는 XMM register를 이용해 넘겨질 것
- 인자 i는 %edi를 통해 넘겨질 것
- 2 ~ 3번재 줄은 x를 double로 converting되는 것을 볼 수 있다.
- 5번째 줄은 i를 double로 converting되는 것을 볼 수 있다.
3.11.4 Defining and Using Floating-Point Constants(부동소수점 상수의 정의 및 사용)
Integer 연산과 달리 AVX의 floating-point 연산들은 operand로 immediate value들을 가지지 않는다.
- 대신, 컴파일러는 constant value를 위해 memory 공간을 할당하고 초기화를 해줘야 한다(must).
- 이후 memory에서 이 값들을 읽는 방식으로 constant value를 지원한다.
예시

C 코드
x86-64 assembly code
상수 1.8을 어떻게 다루는 지 살펴보자.
- 1.8은 현재 .LC2 라고 label된 memory location으로부터 읽어오고 있다.
- 각 label에선 10진수로 된 값들과 함께 두개의 .long 으로 선언된 쌍을 볼 수 있다.
- 이 두개의 .long 으로 1.8을 표현하고 있는 것인데 어떻게 이를 두개의 10진수로 표현하는지를 알아보자.
- 각각의 .long 의 수들을 16진수로 하면 3435973837 → 0xcccccccd 와 1073532108 → 0x3ffccccc 로 표현된다.
- x86-64는 little endian이기 때문에 처음 .long이 하위 4byte로 가게 되고, 두번째 .long이 상위 4byte로 가게 된다.
- 이렇게 했을 때, 이 둘을 8-byte로 읽으면 다음과 같다. → 0x3ffccccc cccccccd
- exponential bit : 0x3ff → 1023이다.
- double-precision의 bias는 1023이므로 지수 E는 0이 된다.
- fraction bit : 0xccccccccccccd
- 0.8이다.

3.11.5 Using Bitwise Operations in Floating-Point Code(부동소수점 코드에서 비트연산 사용하기)

- 이렇게 모든 bit들에 대해 update되는 것을 packed data에 수행된다고 한다.
- 다시 말하자면, bitwise operation들은 operand s1과 s2의 모든 bit들에 수행된다는 것을 뜻한다.
3.11.6 Floating-Point Comparison Operations(부동소수점 비교 연산)
Integer의 CMP instruction과 비슷하다.
- 두개의 operand $s_1$과 $s_2$ 를 비교해서 conditional code를 설정한다.
Operand
- first operand $s_1$ : XMM register 또는 Memory location
- second operand $s_2$ : XMM reigster만 허용
Three Conditional codes
- ZF : zero flag
- CF : carry flag
- PF : parity flag
parity flag에 대해
- integer일 때의 PF : 짝수일 때 1로 설정된다.
- floating-point일 때의 PF : NaN일 때 1로 설정된다.
- x == x 도 x가 NaN일 때는 0을 반환한다.
$s_1$ 과 $s_2$가 다음과 같을 때의 Condition Code를 살펴보자.

- Unordered : operand가 둘 중 하나는 NaN일 때 발생한다.
- 이 Unordered라는 것은 parity flag 를 통해 감지 가능.
- jp 명령어는 floating-point 값 간의 비교에서 unordered result를 야기할 때 jump를 하기 위해 사용한다.
- 위의 unordered인 경우를 제외하면 CF와 ZF의 값은 unsigned integer의 결과와 동일하다.
- ZF : 두 operand가 같을 때 1로 설정
- CF : $s_2 \lt s_1$ 일 때 1로 설정
- ja 와 jb 명령어는 이런 flag들의 다양한 조합의 조건부 jump에 사용된다.
코드

figure 3.51(a) conditional branching in C

figure 3.51(b) conditional branching in assembly code
- 원문 참고
- x < 0.0 The ja branch on line 4 will be taken, jumping to the end with a return value of 0.
- x = 0.0 The ja (line 4) and jp (line 6) branches will not be taken, but the je branch (line 8) will, returning with %eax equal to 1.
- x > 0.0 None of the three branches will be taken. The setbe (line 11) will yield 0, and this will be incremented by the addl instruction (line 13) to give a return value of 2.
- x = NaN The jp branch (line 6) will be taken. The third vucomiss instruction (line 10) will set both the carry and the zero flag, and so the setbe instruction (line 11) and the following instruction will set %eax to 1. This gets incremented by the addl instruction (line 13) to give a return value of 3.
- As an example of floating-point comparisons, the C function of Figure 3.51(a) classifies argument x according to its relation to 0.0, returning an enumerated type as the result. Enumerated types in C are encoded as integers, and so the possible function values are: 0 (NEG), 1 (ZERO), 2 (POS), and 3 (OTHER). This final outcome occurs when the value of x is NaN. Gcc generates the code shown in Figure 3.51(b) for find_range. The code is not very efficient—it compares x to 0.0 three times, even though the required information could be obtained with a single comparison. It also generates floating- point constant 0.0 twice—once using vxorps, and once by reading the value from memory. Let us trace the flow of the function for the four possible comparison results:
3.11.7 Observations about Floating-Point Code(부동소수점 코드에 대한 관찰)
AVX2는 packed data에 대해 parallel 연산으로 동작함으로써 더 빠르게 계산해 낼 잠재력을 지니고 있다. 이에 Compiler 개발자들은 scalar code를 parallel code로의 변환을 자동화하는 작업을 하고 있다. 즉, 현재 가장 신뢰도가 높은, parallelism을 통해 성능을 더 좋게 할 수 있는 방법으로는 data의 vector들을 다루기 위해 GCC에 의해 지원되는 C언어의 확장을 사용하는 것이다. (Web Aside OPT:SIMD, p.582에서 더 알아보기)