![[판다스] 데이터 전처리 (부동산 데이터)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FmLIfO%2Fbtr3WcI1sDx%2FAAAAAAAAAAAAAAAAAAAAAB5RpAba4BV8Uu14L9lPfE-nJvhOS8XOsKp52bZxyf6q%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DLpfLi3p1pT%252Fz4HFta4pRFVxyVjI%253D)
샘플데이터: 공공데이터포털 에서 제공하는 공공데이터 “민간 아파트 가격동향” 를 활용
0. 공공데이터 가져오기
import pandas as pd
df = pd.read_csv('https://bit.ly/ds-house-price')
df
- pandas 라이브러리로 pd.read_csv('경로')를 이용해 df 변수에 데이터프레임을 저장한다.
# 데이터 프레임의 정보확인
df.info()
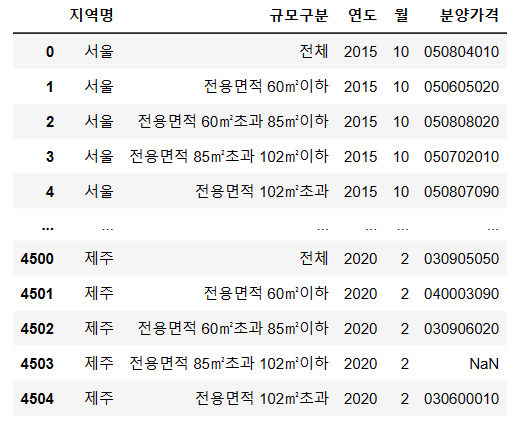
#'분양 가격' 변수에서 4210개의 Non Null 발견 > 295개의 결측치 처리!
1. 컬럼명 수정하기(분양가격(㎡)' > '분양가격')
df.rename(columns = {'분양가격(㎡)':'분양가격'}, inplace = True)
df- df.rename(columns = {'변경 전 열의 이름' :'변경 희망 열의 이름'}) 함수를 이용해준다.
- 여기서 inplace는 False 값이 default이며 변경한 이름을 데이터프레임에 반영하려면 df.rename(columns = {'변경 전 열의 이름' :'변경 희망 열의 이름'}, inplace = True)로 True 값을 넣어준다.
2. "분양가격" 열에서 공백이 있는 데이터의 공백을 삭제해주기
df['분양가격'] = df['분양가격'].str.strip() # 앞 뒤 공백을 제거
#DataFrame.str.strip() 함수는 문자열 Series의 각 값에서 양쪽 공백을 제거한 결과를 반환
#따라서 이 함수는 새로운 Series 객체를 반환한다. 원래 DataFrame은 변경되지 않는다.- df['열의 이름].str.strip() 함수는 데이터 안의 내용에서 앞 뒤 공백을 제거해주는 역할을 한다.
- 반환값이 시리즈이기 때문에 데이터프레임에 수정한 시리즈 값을 입력해주는 것을 잊지 말자.
3. "분양가격" 열에서 데이터 안에 있는 ",", "-" 값을 각각 삭제해주고 데이터가 없는 경우("") 0으로 대체해주기
df['분양가격'] = df['분양가격'].str.replace(',', '')
df['분양가격'] = df['분양가격'].str.replace('-', '')
#DataFrame.str.replace() 함수는 새로운 Series 객체를 반환한다. 원래 DataFrame은 변경되지 않는다.
#df['분양가격'].str.replace('', '0') 이렇게 하면 안됨(숫자 사이 앞 뒤 0이 들어가게 됨 주의)
df.loc[df['분양가격'] == '', '분양가격'] = 0 #loc[행,열]- df['열의 이름].str.replace('데이터 내에서 변경하고 싶은 문자열 부분', '변경하고 싶은 문자열') 함수를 이용한다.
- 반환값이 시리즈이기 때문에 데이터프레임에 수정한 시리즈 값을 입력해주는 것을 잊지 말자.
- df['분양가격'].str.replace('', '0') 이렇게 하면 문자열 사이사이에 0값이 들어가게 되므로 데이터가 없는 경우("") 0으로 대체할 수 없다.
4. "분양가격" 열 안에 있는 Nan 데이터를 삭제하기.
df = df.dropna(subset=['분양가격']).reset_index(drop=True)- df.dropna() 함수는 데이터프레임 내에 Nan(결측치 값)을 모두 제거해준다.
- df.dropna(subset=['열 이름'])은 열 이름에 있는 결측치 값을 모두 제거해준다.
- df.reset_index(drop = True) 함수는 인덱스의 설정을 리셋한다. (인덱스 설정을 리셋하지 않으면 위에서 제거된 결측치가 있던 행들로 인해 인덱스가 불연속적이게 된다)
- 위에서 인자로 drop은 인덱스로 세팅한 열을 DataFrame내에서 삭제할지 여부를 결정한다
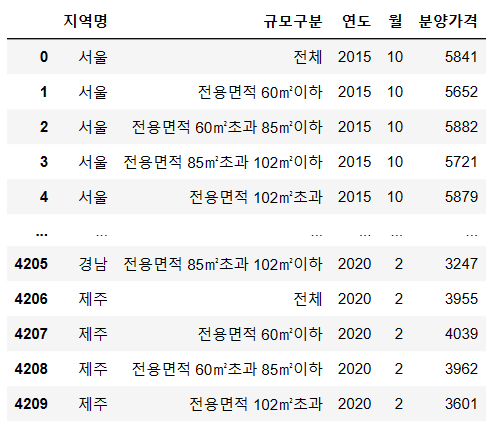
- 4503 번째 행에 Nan 값이 있었는데 해당 행이 삭제되었다.
5. "분양가격" 열의 dtype(데이터타입)을 int로 변환하기
df['분양가격'] = df['분양가격'].astype(int) #특정 행이나 열로 접근하면 시리즈를 반환하기 때문에 데이터프레임에 교체해주는 거 잊지말기
df['분양가격']- df['열 이름'].astype(변경할 데이터 타입) 함수를 이용해 타입 캐스팅을 한다.
- df['열 이름']은 시리즈이기 때문에 시리즈 값을 데이터프레임에 반영해줘야 한다.

6. "규모구분" 열에 있는 데이터 내의 "전용면적" 글자를 삭제해주기
df['규모구분'] = df['규모구분'].str.replace('전용면적 ', '')
df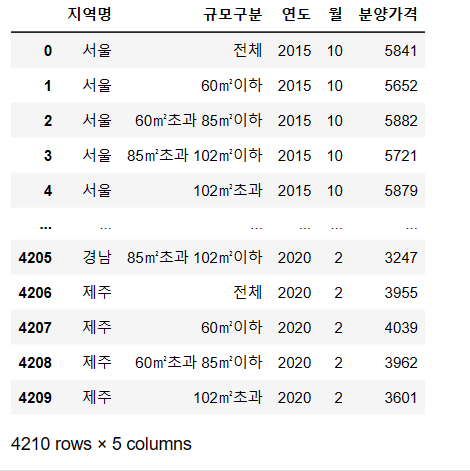
- 위에서 사용했던 replace 함수 이용
7. "규모구분" 열을 기준으로 value count 해주기.
df['규모구분'].value_counts()- df['열 이름'].value_counts() 함수를 호출한다.

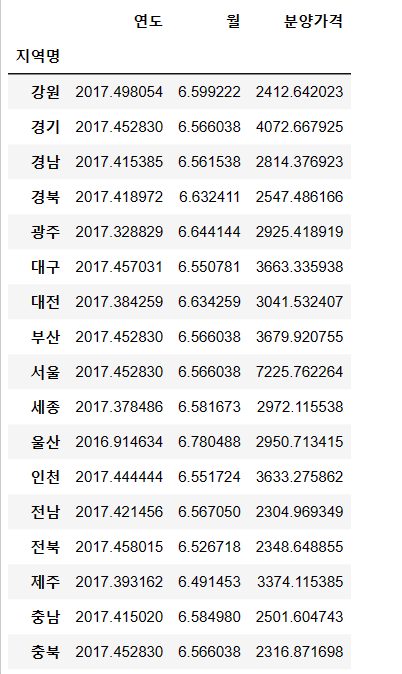
8. 지역명별로 평균 분양가격을 확인
df.groupby('지역명').mean()- df.groupby('열 이름') 함수로 group을 묶어주고 그 뒤로 mean(), max() 등의 함수를 활용한다.
9. 지역별 최고 비싼 분양가를 확인
df.groupby('지역명').max()
10. 지금까지 작업한 데이터프레임을 csv 파일로 저장하기
df.to_csv('ds-house-price_clean.csv', index=False)- df.to_csv('저장할 파일의 이름 설정', index = True or False) 함수를 이용해 저장한다.
- (Index 부분은 인덱스의 출력 여부 이다. False일 경우 인덱스를 출력하지 않는다.)
- csv 파일은 파이썬 파일이 저장되어 있는 폴더에 저장된다.

