![[CSAPP] 8.1 Exceptions(예외)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FEOCdj%2Fbtr0KGtQ46R%2FAAAAAAAAAAAAAAAAAAAAAEFSPXiw2BliklSdr8W74Y8xUXwE2Q7QWMqnxwiOPaOy%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DSICi9JcQgUF8Dx%252FjAu85qP5DyBI%253D)
개요
control flow
processor는 전원이 공급되고 끊기는 순간까지 Program Counter는 다음의 순서값을 가정한다.

즉, Instruction이 I_k에서 I_k+1로의 일련의 순서를 갖는 명령어를 기대한다고 할 수 있다.
이 때 control transfer이란, a_k에서 a_k+1로 이동하는 것을 말한다. 이러한 transfer의 연속적인 것을 control flow 라고 한다.
Control flow의 종류
- Smooth : I_k와 I_k+1이 메모리 상에 인접해 있는 것을 말한다.
- 이 smooth sequence에서도 I_k와 I_k+1이 인접하지 않은 경우가 생기는데, 이는 call, jumps , return 과 같은 명령어에 의해 발생된다.
- 이는 프로그램 내부 program state(프로그램 변수 등)의 변화에 반응하기 위해 필요한 매커니즘이다.
- 그럼 system state에 반응하기 위해서는 어떻게 해야 할까? 위와 같은 program state로 잡을 수 없는 것들이 있다.
- 예1) hardware timer이 규칙적으로 진행되는 것
- 예2) packet들이 network adapter로 도착하고, memory에 저장되어야 하는 것
- 예3) program이 disk에서 데이터를 요청한 후 data가 준비되었다고 알림 받기 전까지 sleep하고 있는 것
- 예4) 부모 프로세스는 children process들이 종료될 때 알림을 받아야 하는 것
- modern processor에서는 이러한 상황을 exceptional control flow(ECF)을 통해 반응한다.
- ECF
- 모든 computer system 계층에서 발생한다.
- hardware level : hardware에 의해 감지되는 이벤트들이 exception handler들로 이동되게끔 control transfer를 깨뜨린다.
- OS level : kernel은 context switch를 통해 하나의 user process에서 다른 process로 control을 이동시킨다.
- application level : process는 다른 process에 signal을 보낸다. 이는 수신자의 signal handler로 control을 이동시키는 exception flow이다.
- 다른 예) nonlocal jump(기존 stack의 규칙을 사용하지 않는 방식) - c++과 java에선 try-catch-throw 구문을 말함
왜 ECF를 이해하는 것이 중요한가?
- 중요한 system 개념들을 이해하는 데에 도움이 된다.
- OS가 I/O, process들, virtual memory 등을 구현하기 위해 사용하는 매커니즘
- application이 OS와 상호작용하는 방법들을 이해하는 데에 도움이 된다.
- trap이나 system call들을 사용해서 OS에게 어떠한 ‘서비스’를 요청한다.
- disk에 데이터를 쓸 때, network로부터 데이터를 읽을 때, 새로운 프로세스를 만들 때, 현재 프로세스를 종료할 때, 이 전부다 system call을 통해 수행이 가능한 것들이다.
- 기본적인 system call 매커니즘을 이해한다면 어떻게 이러한 ‘서비스’들이 application들한테 제공이 되는 것인지를 이해할 수 있다.
- 흥미로운 application 프로그램을 짜는 데에 도움이 된다.
- OS는 application 프로그램에 powerful한 ECF 매커니즘을 제공해준다.
- 새 process를 생성
- process가 종료되기까지 wait하는 것
- system에서의 exceptional event를 다른 process에 알리는 것
- 또한 이러한 이벤트들을 감지하고 반응하는 것
- 이러한 것들을 이용해서 Unix shell 또는 Web server와 같은 프로그램들을 짤 수 있게 된다.
- OS는 application 프로그램에 powerful한 ECF 매커니즘을 제공해준다.
- 동시성(concurrency)에 대해 이해하는데에 도움이 된다.
- 바로 ECF가 이러한 동시성 매커니즘을 구현하는데에 기본 매커니즘이 되기 때문이다.
- exception handler : application 프로그램의 실행을 차단(interrupt)한다.
- process and theads : 시간 상에서 실행이 겹치는 것들
- signal handler: application 프로그램의 실행을 차단(interrupt)하는 것
- 이러한 동시성에 대해선 chapter12에서 더 자세히 다룰 것이다.
- 어떻게 software exception이 동작하는 지를 이해하는 데에 도움이 된다.
- c++과 java에선 : try-catch-throw 구문들
- c에선 : setjmp, longjmp 함수들
- 이러한 software적인 exception들은 프로그램이 nonlocal jump를 하도록 한다.
- nonlocal jump란? 기존 call/return stack 규칙을 지키지 않은 jmp라고 할 수 있다. 즉 현재 stack에서 다른 stack으로 바로 건너 뛰는 것을 말한다.
- 이는 application-level ECF에 해당한다.
- 이러한 low-level 함수들을 이해하게 되면 더 상위 level의 software적인 exception들이 어떻게 구현될 수 있는지를 이해하는데에 도움이 된다.
현재까지는 application과 hardware가 어떻게 상호작용하는지를 학습했었다. 이번 8장에서는 어떻게 application이 OS와 상호작용하는지부터 살펴볼 예정이다. 이후에 system call과 더불어서 추상화 단계로 이동해서 process와 signal들을 설명할 것이고, 마지막으로는 nonlocal jump등의 application level의 ECF를 살펴볼 것이다.
8.1 Exceptions
exception이란 어느 부분은 hardware에 의해, 어떤 부분은 OS에 의해 구현된 exceptional control flow이다. 여기서는 일반적인 exception들과 exception handling에 대한 이해를 제공할 거고, modern computer system의 혼란스러운 측면들의 비밀을 제거하는 데에 도움을 줄 것이다.
Exception
어느 processor의 state의 변화에 반응하여 control flow를 변경하는 것을 말한다.
- state : processor 내부에서 다양한 bit들과 signal들로 encode되어 있는 것.
- event : 이런 state의 변화를 말한다.
Event
- 현재 instruction과 직접적인 연관이 있는 event : virtual memory page fault, 산술 overflow, 0으로 나누는 시도 등
- 현재 instruction과 직접적인 연관이 없는 event : system timer가 끝나는 것, I/O 요청이 완료되는 것
- 공통점 : processor가 event를 감지 → exception table이라는 jump table을 통해 간접적인 procedure call을 만들어냄 → 이는 OS subroutine(exception handler)이라는 곳으로 jump하게됨 → 이 OS subroutine은 특정 종류의 이벤트를 처리하도록 특별히 설계된 것. → 이 exception handler가 끝나면, 어떤 종류의 이벤트냐에 따라 다음 세가지가 일어남.
- exception handler는 현재 instruction으로 control을 반환시킨다. 이 현재 instruction은 exception이 발생했던 instruction을 말한다.
- 다음 instruction으로 control을 반환시킨다. 이 다음 instruction은 exception이 발생하지 않았던 instruction이다.
- interrupt(exception)를 받았던 프로그램을 종료시킨다.
8.1.1 Exception handling
exception을 handling한다는 것은 하드웨어와 소프트웨어간의 긴밀한 협력을 포함하고 있기 때문에 이해하기 어려울 수도 있다. 여기서 혼란스러울 수 있는 부분으로는, ‘어떤 component(구성 요소)가 어떠한 task를 맡고 있는지’가 있다.
hardware와 software간의 분업
- 각 system에서의 가능한 exception 종류에는 non-negative 정수형 번호(exception number)를 부여 받는다.
- 어떤 번호들은 processor 설계자들에 의해 부여받고,
- 예) 0으로 나누기, page fault, memory access 위반, break point, 산술 overflow 등
- 나머지 번호들은 OS kernel 설계자들에 의해 부여받는다.
- 예) system call, 외부 I/O 디바이스로부터의 signal 등
- 어떤 번호들은 processor 설계자들에 의해 부여받고,
- system에 전원이 인가되거나 reset될 때, OS는 exception table이라는 jump table에 대한 공간을 할당하고 초기화 한다.
- 이에 따라 k개의 table 항목들에 대해 exception handler k개의 각각의 주소를 포함하도록 한다.Figure 8.2. Exception table
- run-time에서는, processor가 event가 발생햇다는 것을 감지하고, 그에 일치하는 exception number k를 결정한다.
- 이에 따라 processor는 해당 exception table의 k번째 항목에 있는 주소로 ‘indirect procedure call’을 발생시킴으로써 exception을 수행하게 된다.Figure 8.3. processor가 적절한 exception handler의 주소를 알기 위해 exception table을 사용하는 방법에 대해 묘사하고 있다.

-
- exception number라는 것은 결국엔 exception table의 index를 뜻하는 것이고, 이 table의 첫 주소는 특별한 CPU register인 exception table base register에 저장되어 있다.
- Procedure call V.S. Exceptionprocedure call exception
| procedure call | exception |
| processor는 handler로 branching되기 전에 return address를 stack에 push한다. | return address는 현재 instruction일 수도 있고, 다음 instruction일 수도 있다. |
| 추가적으로 processor state를 stack에 push한다. 이 processor state는 handler가 반환되고 interrupted된 프로그램을 다시 시작할 때 필요한 것들이다. (예: x86-64 system에선, 현재 condition code들을 담고 잇는 EFLAGS register를 다른 것들과 함께stack에 push한다.) | |
| user program에서 kernel로 control이 이동될 때, 이러한 것들은 stack에 push되는데, user stack이 아닌 kernel의 stack에 push된다. | |
| kernel mode에서 실행된다. 이는 모든 system resource들을 접근하는 권한이 있다는 뜻이다. |
- 한번 exception이 trigger되면, 나머지 작업들은 software적인, exception handler에 의해 처리된다.
- handler가 event를 처리한 이후, 선택적으로 ‘return from interrupt’라는 instruction을 실행함으로써 인터럽트된 프로그램으로 return시킨다.
- return from interrupt instruction : 적절한 state를 processor의 control(PC)와 data register들로 다시 pop한다.
- 만약 exception이 user program을 인터럽트 했었다면 user mode로 state를 복구시키고, 인터럽트된 프로그램에 control을 반환한다(인터럽트 된 프로그램의 해당 instruction으로 PC를 다시 설정한다는 뜻).
- return from interrupt instruction : 적절한 state를 processor의 control(PC)와 data register들로 다시 pop한다.
8.1.2 Classes of Exceptions
Exception은 4가지 클래스로 나눌 수 있다.
- interrupts
- traps
- faults
- aborts

Interrupt
processor의 외부에 있는 I/O device에서의 signal의 결과로서, 비동기적으로 발생한다.
hardware interrupt
- 하드웨어 인터럽트는 비동기적이라고 할 수 있는데, 이는 어느 특정한 instruction에 의해서도 발생하지 않는 면에서 그렇다고 할 수 있다.
- hardware interrupt를 위한 exception handler를 interrupt handler라고 부르기도 한다.
hardware interrupt의 과정들

I/O 장치들(network adapter, disk controller, timer chip등)은 processor chip에 있는 pin에 신호를 보냄으로서 interrupt를 트리거 할 수 있다.
- 이는 system bus에 해당 interrupt를 유발한 장치를 가리키는 exception number를 실어줌으로써 신호를 보낸다.
- 현재 instruction의 실행이 끝나면, processor는 interrupt pin이 HIGH로 가있는 것을 알아차리게 된다.
- 이에 exception number를 system bus로부터 읽고, 적절한 interrupt handler를 호출하게 된다.
- 이후 handler가 끝나게 되면, next instruction으로 control을 반환한다.
- 이러한 실행들로 인해, 프로그램은 마치 interrupt가 발생하지 않은 것처럼 계속 실행되는 효과가 있다.
나머지 exception 클래스들은 현재 instruction 실행의 결과로서, 전부 동기적으로 발생한다. 이러한 instruction들을 faulting instruction이라고 부를 것이다.
Traps and System calls
Traps
- instruction의 실행 결과로서 발생되는 의도적인 exception이다.
- interrupt handler와 마찬가지로 trap handler는 next instruction으로 control을 반환한다.
- trap의 가장 중요한 사용성은 user 프로그램과 kernel 사이의 procedure-like 인터페이스를 제공하는 것이다.
- 이러한 procedure-like 인터페이스는 system call이다.
- system call
- user 프로그램에서는 kernel 로부터 어떠한 ‘서비스’를 요청할 필요가 있다.
- file을 읽는 것(read)
- 새 process를 생성하는 것(fork)
- 새 프로그램을 실행하는 것(execve)
- 현재 프로세스를 종료하는 것(exit)
- 이러한 kernel service에 접근하기 위해 processor는 user 프로그램이 어떠한 서비스를 원할 때, 이를 실행시킬 수 있는 syscall instruction을 제공한다.
- user 프로그램에서는 kernel 로부터 어떠한 ‘서비스’를 요청할 필요가 있다.
syscall instruction의 과정

이러한 syscall instruction을 실행시킴 → exception handler를 trap시킴 → 인자들을 해석하고 kernel의 적절한 routine을 호출함
- programmer 입장에서는일반 함수 호출과 다를바 없어 보인다. 하지만 그 실행에 있어서는 사뭇 다르다.
- Regular function V.S. Syscall instructionRegular function syscall instruction
Regular function syscall instruction
| user mode에서 실행된다. 즉, 실행할 수 있는 instruction의 종류가 제한되어 있고, 함수를 호출하는 스택과 동일한 stack에 접근한다. | kernel mode에서 실행된다. 이는 특권을 가지는 instruction을 실행하는 것이 허용되고, kernel에서 정의되고 있는 stack에 접근 가능하다. |
Faults
handler가 정정할 수 있을지도 모르는 error condition으로부터 발생한다.
Fault의 실행 과정
fault가 발생하게 되면, processor는 fault handler로 control을 이동시킨다.

- 만약 handler가 error condition을 정정할 수 있다면, faulting instruction으로 control이 넘어가고, 이 instruction을 다시 실행하게 된다.
- 만약 정정할 수 없는 error condition이라면, handler는 kernel의 abort routine으로 반환된다.
- abort routine : fault를 유발한 application program을 종료한다.
Fault의 예
- page fault exception : instruction이 virtual address를 참조하려고 할 때, 이 address에 대한 page가 memory에 존재하지 않을 때 발생한다. 이에 따라 disk에서 page를 가져와야 한다.(9장에서 나오는 내용이다).
- page : virtual address에서 보통 4kb되는 연속적인 block을 의미한다.
- page fault handler는 적절한 page를 disk로부터 load하고, fault가 발생된 instruction으로 control을 반환하게 된다.
- 이후 이 instruction이 다시 실행되면, 해당 page는 이제 memory에 거주하게 되고, 이에 따라 faulting 없이 수행할 수 있게 되는 것이다.
Aborts
복구할 수 없는 치명적인 오류의 결과이다. 전형적으로 hardware에러에 의해 발생한다.
- 예) DRAM이나 SRAM bit가 망가질 때 발생하는 parity error(TODO: 찾아보자)
- 우주 방사선에 의한 dram 또는 sram의 손상 등
Abort의 실행 과정
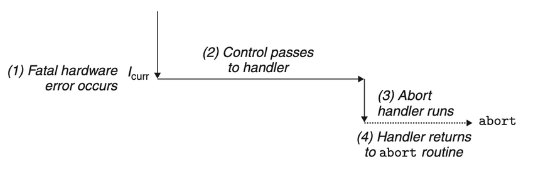
- Abort handler는 application 프로그램으로 control을 절대 반환하지 않는다.
- handler는 단지 abort routine이라는 application 프로그램을 종료시키는 곳으로 control을 반환한다.
8.1.3 Exception in Linux/x86-64 Systems
더 구체적으로 하기 위해 x86-64 system에서 정의된 exception들을 몇가지 살펴보자.
x86-64 system에서의 exception들

- 256가지의 exception type들이 있다.
- 0 ~ 31 : 인텔 설계자들에 의해 정의된 exception들이다.(어느 x86-64 system에서든간에 동일하다.)
- 32 ~ 255 : OS에 의해 정의된 interrupt 또는 trap들에 대한 exception들이다.
Linux/x86-64 Faults and Aborts
Divide error General protection fault Page fault Machine check
| 0번 exception | 13번 exception | 14번 exception | 18번 exception |
| 응용프로그램에서 0으로 나누는 시도를 할 때, 혹은 divide instruction의 결과가 매우 클 때 발생한다. | 많은 이유들로 인해 발생되는데, 보통은 virtual address의 정의되지 않은 영역을 참조하려 할 때, 혹은 read-only text 영역에 write하려 시도할 때 발생된다. | faulting이 일어난 instruction이 재시작되는 exception의 한 예시이다. | 치명적인 hardware error에 의해 발생된다. 이는 faulting instruction의 실행 동안 감지된다. |
| Unix는 divide error에 대한 복구를 시도하지 않고, 대신 프로그램을 abort(종료)한다. | Linux는 이러한 fault에 대해 복구하려고 시도하지 않는다. | handler는 disk에 있는 적절한 virtual memory의 page와 physical memory에 있는 page를 연관시킨 후에 faulting이 일어난 instruction을 다시 실행시킨다. | machine check handler는 응용 프로그램으로 control을 절대 넘겨주지 않는다. |
| Linux shell은 보통 divide error를 ‘Floating exceptions’ 라고 보여준다. | Linux shell에서는 보통 이러한 general protection fault를 “Segmentation faults”라고 알려준다. |
Linux/x86-64 System Calls
linux는 수백여개의 system call들을 제공하고 있다.

- TODO: jump table VS exception table
- C program에서는 syscall 함수들을 사용함으로써 system call을 호출시킬 수 있다.
- 실상 이러한 필요성은 별로 없다. 이유는 C 표준 라이브러리에서 편리한 wrapper function들을 제공해주기 때문이다.
- wrapper function : 인자들을 포함하여 kernel의 적절한 system call instruction으로 trap을 유발 → system call의 return status를 호출한 프로그램으로 전달
- 이러한 것으로 봤을 때, system call과 이거와 관련된 wrapper function들을 system-level function이라고 할 것이다.
- syscall : system call은 trapping instruction을 통해 제공되는데, 이 trapping instruction을 syscall이라고 한다.
- Linux system은 모든 인자들을 stack이 아닌 6개까지는 general-purpose register(%rdi, %rsi, %rdx, %r10, %r8, %r9)들을 통해 전달한다.(convention적인 부분들이다.)
- %rax : syscall 번호를 담고 있다.
- %rdi : 첫번째 인자를 담고 있다.
- %rsi : 두번째 인자를 담고 있다.
- 그 나머지 인자들도 각 나머지 register에 담겨 있다.
- system call로부터 반환될 때는, %rcx와 %r11 레지스터가 파괴되고, %rax는 return 값을 포함하게 된다.
- return value: -4095~ -1까지는 negative errno와 일치하는 error이다.
- write, _exit system call로 예시를 들고 있음

'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [CSAPP] 8.7 Tools for Manipulating Process (0) | 2023.02.28 |
|---|---|
| [CSAPP] 8.6 Nonlocal Jumps(논로컬 점프) (0) | 2023.02.28 |
| [CSAPP] 8.4 Process Control(프로세스 컨트롤) (0) | 2023.02.27 |
| [CSAPP] 8.5 Signal(시그널) (0) | 2023.02.22 |
| [CSAPP] 7.9 Loading Executable Object Files(실행 가능한 객체 파일 로딩) (0) | 2023.02.21 |